[프로그래머스 python]후보키
2020-06-13https://programmers.co.kr/learn/courses/30/lessons/42890
문제
프렌즈대학교 컴퓨터공학과 조교인 제이지는 네오 학과장님의 지시로, 학생들의 인적사항을 정리하는 업무를 담당하게 되었다.</br> 그의 학부 시절 프로그래밍 경험을 되살려, 모든 인적사항을 데이터베이스에 넣기로 하였고, 이를 위해 정리를 하던 중에 후보키(Candidate Key)에 대한 고민이 필요하게 되었다.</br> 후보키에 대한 내용이 잘 기억나지 않던 제이지는, 정확한 내용을 파악하기 위해 데이터베이스 관련 서적을 확인하여 아래와 같은 내용을 확인하였다.</br> 관계 데이터베이스에서 릴레이션(Relation)의 튜플(Tuple)을 유일하게 식별할 수 있는 속성(Attribute) 또는 속성의 집합 중, 다음 두 성질을 만족하는 것을 후보 키(Candidate Key)라고 한다. 유일성(uniqueness) : 릴레이션에 있는 모든 튜플에 대해 유일하게 식별되어야 한다. 최소성(minimality) : 유일성을 가진 키를 구성하는 속성(Attribute) 중 하나라도 제외하는 경우 유일성이 깨지는 것을 의미한다. 즉, 릴레이션의 모든 튜플을 유일하게 식별하는 데 꼭 필요한 속성들로만 구성되어야 한다. 제이지를 위해, 아래와 같은 학생들의 인적사항이 주어졌을 때, 후보 키의 최대 개수를 구하라.</br> 그림의 예를 설명하면, 학생의 인적사항 릴레이션에서 모든 학생은 각자 유일한 학번을 가지고 있다. 따라서 학번은 릴레이션의 후보 키가 될 수 있다. 그다음 이름에 대해서는 같은 이름(apeach)을 사용하는 학생이 있기 때문에, 이름은 후보 키가 될 수 없다. 그러나, 만약 [이름, 전공]을 함께 사용한다면 릴레이션의 모든 튜플을 유일하게 식별 가능하므로 후보 키가 될 수 있게 된다. 물론 [이름, 전공, 학년]을 함께 사용해도 릴레이션의 모든 튜플을 유일하게 식별할 수 있지만, 최소성을 만족하지 못하기 때문에 후보 키가 될 수 없다. 따라서, 위의 학생 인적사항의 후보키는 학번, [이름, 전공] 두 개가 된다.</br> 릴레이션을 나타내는 문자열 배열 relation이 매개변수로 주어질 때, 이 릴레이션에서 후보 키의 개수를 return 하도록 solution 함수를 완성하라.
제한사항 relation은 2차원 문자열 배열이다. relation의 컬럼(column)의 길이는 1 이상 8 이하이며, 각각의 컬럼은 릴레이션의 속성을 나타낸다. relation의 로우(row)의 길이는 1 이상 20 이하이며, 각각의 로우는 릴레이션의 튜플을 나타낸다. relation의 모든 문자열의 길이는 1 이상 8 이하이며, 알파벳 소문자와 숫자로만 이루어져 있다. relation의 모든 튜플은 유일하게 식별 가능하다.(즉, 중복되는 튜플은 없다.)
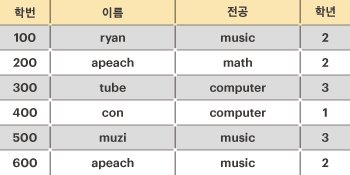
입출력 예
| relation | result |
|---|---|
[["100","ryan","music","2"],["200","apeach","math","2"],["300","tube","computer","3"],["400","con","computer","4"],["500","muzi","music","3"],["600","apeach","music","2"]] |
2 |
2019 KAKAO BLIND RECRUITMENT 의 기출문제
테이블의 컬럼들로 나올수있는 조합을 모두 찾아낸다. [학번, 이름, 전공, 학년, 학번이름, 학번전공, 학번학년, 이름전공, 이름학년, 전공학년, 학번이름전공, 학번이름학년, 학번전공학년, 이름전공학년, 학번이름전공학년] 컬럼이 4개인 경우 이렇게 모두 15가지 경우가 나오게된다.
이렇게 만든 조합들에 들어있는 레코드 수가 문제에 주어진 레코드 수와 같다면 그 컬럼은 후보키가 될수있다.
비트연산을 이용해서 학번 이름 전공 학년을 가지고 조합을 만들고 조건을 만족하는 키들중 최소한을 찾아낸다.
def solution(relation):
answer_list = list()
# 순열을 만들기 위해 비트연산을 이용
for i in range(1, 1 << len(relation[0])):
tmp_set = set()
for j in range(len(relation)):
tmp = ''
for k in range(len(relation[0])):
if i & (1 << k):
tmp += str(relation[j][k])
tmp_set.add(tmp)
if len(tmp_set) == len(relation):
not_duplicate = True
for num in answer_list:
# 이미 정답에 들어있는 컬럼과 겹친다면 그것은 중복임으로 제외
if (num & i) == num:
not_duplicate = False
break
if not_duplicate:
answer_list.append(i)
return len(answer_list)
참조
http://blog.naver.com/PostView.nhn?blogId=jaeyoon_95&logNo=221756357659&categoryNo=0&parentCategoryNo=0&viewDate=¤tPage=1&postListTopCurrentPage=1&from=postView