[python]알아두면 좋을 파이썬 3.9의 새로운 기능
2020-05-17이글은 해외 블로그의 글을 번역한 글입니다.
좋은글 써주시고 번역을 허락해주신 martin heinz에게 감사를 표합니다.
https://martinheinz.dev/blog/21
https://medium.com/@martin.heinz/new-features-in-python-3-9-you-should-know-about-14f3c647c2b4
Python 3.9의 출시는 아직도 한참 남아 있지만(2020-10-05), 마지막 알파(3.9.0 a6)가 출시되었고 가까운 미래(2020-05-18)에 첫번째 베타 버전이 출시됨에 따라 새로운 기능, 개선 사항 및 수정 사항을 확인할 때가 된 것 같습니다. 이 기사는 모든 변경사항에 대한 완전한 목록이 아니라 다음 버전에서 제공 될 가장 흥미롭고 주목할만한 사항을 적은것입니다. 자 그럼 출발해 봅시다!
# 베타 버전 설치
Python 3.9 의 alpha/beta 버전에 포함된 것들을 시도해보려면 먼저 설치를 해야합니다. 이상적으로 기존의 Python 3.8 (또는 다른 stable 버전) 인터프리터를 엉망으로 만들지 않습니다. 가장 최신 버전을 설치하려면 다음을 수행하십시오.
wget https://www.python.org/ftp/python/3.9.0/Python-3.9.0a5.tgz
tar xzvf Python-3.9.0a5.tgz
cd Python-3.9.0a5
./configure --prefix=$HOME/python-3.9.0a5
make
make install
$HOME/python-3.9.0a5/bin/python3.9
이 프로그램을 실행한 후에는 IDLE과 다음과 같은 메시지가 표시됩니다.
Python 3.9.0a5 (default, Apr 16 2020, 18:57:58)
[GCC 9.2.1 20191008] on linux
Type "help", "copyright", "credits" or "license" for more information.
# 새로운 딕셔너리 연산자
가장 주목할 만한 새로운 기능은 아마도 새로운 딕셔너리 병합 연산자인 | 과 |=일 것입니다.지금까지는 다음 세가지 옵션 중 하나를 선택해야 했습니다.
# 병합할 dict
d1 = {"x": 1, "y": 4, "z": 10}
d2 = {"a": 7, "b": 9, "x": 5}
# 병합 후 예상되는 출력
{'x': 5, 'y': 4, 'z': 10, 'a': 7, 'b': 9}
# ^^^^^ 'x'는 d2의 'x' : 5로 덮어써졌습니다.
# Option 1
d = dict(d1, **d2)
# Option 2
d = d1.copy() # d1을 d로 복사
d.update(d2) # d2를 d에 추가
# Option 3
d = {**d1, **d2}
위의 첫 번째 옵션은 dict(iterable, **kwargs) 새로운 딕셔너리를 만드는 함수를 사용 합니다. 첫 번째 인수는 일반적인 딕셔너리이고 두 번째 인수는 키 / 값 쌍의 목록입니다. 이 경우에는 **연산자를 사용하여 unpack한 또 다른 딕셔너리를 사용합니다.
두 번째 방법은 update함수를 사용 하여 첫 번째 딕셔너리에 두 번째 딕셔너리를 추가합니다. 이것은 원본 딕셔너리를 수정하기 때문에 원본을 수정하지 않도록 첫 번째 변수를 다른 변수에 복사해야합니다.
마지막으로 제 생각에 가장 깔끔한 해결책은 두개의 딕셔너리(d1, d2)를 unpack하여 결과를 d에 저장하는 것 입니다.
위의 방법은 여전히 유효하지만 이제 |연산자를 사용하는 새롭고 더 나은 솔루션이 있습니다.
# d에 d1과 d2를 병합한 결과를 저장
d = d1 | d2
# d = {'x': 5, 'y': 4, 'z': 10, 'a': 7, 'b': 9}
# d1에 d2를 추가
d1 |= d2
# d1 = {'x': 5, 'y': 4, 'z': 10, 'a': 7, 'b': 9}
첫번째 예는 이전에 설명한 unpack을 이용한 방법d = {**d1, **d2}과 매우 유사합니다.
두번째 예는 원본 딕셔너리(d1)에 새로운 딕셔너리(d2)를 추가하는 경우 사용할 수 있습니다.
# 위상 정렬
다음으로 흥미로운 새 기능은 functools모듈의 TopologicalSorter클래스입니다. 이 클래스를 사용하면 그래프를 위상 정렬 할 수 있습니다. 그게 뭔데요? 라고 물어본다면, 위상정렬은 유향 그래프의 엣지 u->v가 연결될 수 있는 순서입니다.
이 기능이 등장하기 전에는 칸의 알고리즘이나 깊이 우선 탐색을 이용하여 직접 구현해야 했습니다.
예를 들어 순서가 종속된 작업을 정렬해야 하는 경우 다음과 같이 해보세요.
from functools import TopologicalSorter
graph = {"A": {"D"}, "B": {"D"}, "C": {"E", "H"}, "D": {"F", "G", "H"}, "E": {"G"}}
ts = TopologicalSorter(graph)
list(ts.static_order())
# ['H', 'F', 'G', 'D', 'E', 'A', 'B', 'C']
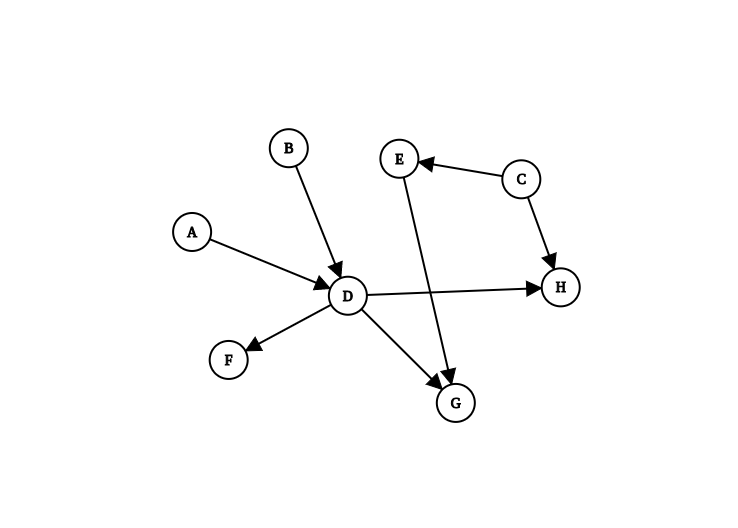
위의 예에서는 Key가 시작하는 노드이고 Value가 방문가능한 노드의 집합인 딕셔너리를 사용하여 그래프를 만듭니다. 그런 다음 그래프를 사용하여 TopologicalSorter()의 인스턴스를 생성한 다음static_order함수를 호출하여 정렬을 합니다. 노드가 그래프의 동일한 수준에 있으면 삽입된 순서대로 정렬하기 때문에 이 순서는 삽입 순서에 따라 달라질 수 있습니다.
static_order() 외에도 이 클래스는 처리할 준비가 된 노드의 병렬 처리도 지원합니다.
이는 작업 대기 열과 같은 것을 만들 때 유용합니다. Python라이브러리 문서에서 이러한 예시 를 확인할 수 있습니다.
# IPv6 범위 주소
Python 3.9에서 도입 된 또 다른 기능은 IPv6 주소 범위(scope)를 지정하는 기능입니다. IPv6 scope에 익숙하지 않은 경우 인터넷의 어느 부분이 유효한 IP 주소인지 지정하는데 사용됩니다. scope는 IP 주소의 끝에 %부호를 사용하여 지정할 수 있습니다. 예를 들면 3FFE:0:0:1:200:F8FF:FE75:50DF%2.-이 IP 주소의 범위 %2는 링크 로컬 주소입니다.
따라서 파이썬에서 IPv6 주소를 처리해야 할 경우 다음과 같이 할 수 있습니다.
from ipaddress import IPv6Address
addr = IPv6Address('ff02::fa51%1')
print(addr.scope_id)
# "1" - interface-local IP address
IPv6범위를 사용할 때 주의해야 할 사항이 있습니다. 기본 연산자를 사용하여 비교할 때는 scope가 다른 두 주소가 동일하지 않습니다.
# math의 새로운 기능들
한편 math모듈에서는 다양한 기능이 추가되거나 향상되었습니다. 기존 기능을 개선한 다음 함수로 시작해볼까요
import math
# 최대공약수
math.gcd(80, 64, 152)
# 8
이전 버전의math.gcd()에서는 최대 공약수를 계산하는 함수는 2개의 인수를 사용할 수 밖에 없어서 프로그래머들이 math.gcd(80, math.gcd(64, 152))와 같은 작업을 하도록 강요했습니다. Python3.9부터는 더 많은 숫자를 사용할 수 있습니다.
math모듈에 새로 추가 된 math.lcm기능 은 다음과 같습니다.
# 최소공배수
math.lcm(4, 8, 5)
# 40
math.lcm()은 인수의 최소 공배수를 계산합니다. math.gcd()와 마찬가지로 가변 개수의 인수를 허용합니다.
남은 두 가지 새로운 기능math.nextafter및 math.ulp는 서로 큰 관련이 있습니다.
# Next float after 4 going towards 5
math.nextafter(4, 5)
4.000000000000001
# Next float after 9 going towards 0
math.nextafter(9, 0)
8.999999999999998
# Unit in the Last Place
math.ulp(1000000000000000)
0.125
math.ulp(3.14159265)
4.440892098500626e-16
math.nextafter(x, y)기능은 매우 간단합니다 - 그 후 다음 부동의 x향해 y고려 부동 소수점 숫자 정밀도로하면서.
반면 math.ulp에 ULP는 "마지막 장소의 단위"를 나타내며 숫자 계산의 정확도를 측정하는 데 사용됩니다. 가장 간단한 설명은 예제를 사용하는 것입니다.
64 비트 컴퓨터가 없다고 가정 해 봅시다. 대신, 우리가 가진 모든 것은 단지 3 자리입니다. 이 3 자리 숫자로 우리는 같은 숫자를 나타낼 수 3.14있지만, 그렇지 않습니다 3.141. 로 3.14표시 할 수있는 가장 큰 숫자는입니다 3.15.이 두 숫자는 1 ULP (마지막 위치의 단위)만큼 다릅니다 0.1. 따라서 math.ulp반환되는 것은이 예제와 동일하지만 실제 컴퓨터의 정밀도와 동일합니다. 적절한 예와 설명은 https://matthew-brett.github.io/teaching/floating_error.html 에서 멋진 글을 참조하십시오 .
# 새로운 문자열 함수
새로운 기능을 가진 것은 math모듈뿐이 아닙니다. 문자열에 대한 두가지 편의 기능도 추가되었습니다.
# Remove prefix
"someText".removeprefix("some")
# "Text"
# Remove suffix
"someText".removesuffix("Text")
# "some"
이 두 함수는 string[len(prefix):]와 string[:-len(suffix)]를 이용한 결과를 수행합니다 . 매우 간단한 기능이지만 이러한 작업을 자주 수행 할 수 있다는 점을 고려하면 내장 기능을 사용하는 것이 좋습니다.
# 보너스 : HTTP코드
마지막이지만 중요한 건, 사실은… HTTP상태 코드가 에 추가되었습니까?http.HTTPStatus. 즉, 다음과 같은 항목이 있습니다.
import http
http.HTTPStatus.EARLY_HINTS
# <HTTPStatus.EARLY_HINTS: 103>
http.HTTPStatus.TOO_EARLY
# <HTTPStatus.TOO_EARLY: 425>
http.HTTPStatus.IM_A_TEAPOT
# <HTTPStatus.IM_A_TEAPOT: 418>
이 상태 코드를 살펴보면 왜 그 코드를 사용하는지 알 수 없습니다. 즉, 마침내 우리가 418 I'm a Teapot 상태 코드를 처리할 수 있게 되었습니다. http.HTTPStatus.IM_A_TEAPOT프로덕션 서버 에서이 코드를 반환 할 때 사용할 수있는 훌륭한 삶의 질 향상입니다 ( 반어법 , 제발 절대 그렇게하지 마십시오 …).
결론
아마도 이러한 모든 변경 사항이 일일 프로그래밍과 관련이있는 것은 아니지만 적어도 처음 2 개의 추가 ( |연산자 및 TopologicalSorter)를 알고 있으면 어느 시점에서 유용 할 수 있으므로 좋을 것 같습니다. 파이썬 3.9는 아직 알파 단계이므로 18.5.2020 (첫 번째 베타 릴리스) 까지 추가 변경 사항이있을 수 있습니다 . 그러나이 버전은 안정적이지 않고 생산 준비가되어 있지 않기 때문에 적어도 10월(정식 출시)까지는 사용해서는 안됩니다.
참조
- https://docs.python.org/3.9/whatsnew/3.9.html
- http://python.org/downloads/release/python-390a5/